A great way to approach Git, I believe, is to explore its inner workings. To do that, let’s take a closer look at an analogy I made up previously, and create some useful graphs from real repositories.
Almost two years ago, in From Subversion to Git: Snapshots, I attempted to compare Git to a naive backup approach (using tar or zip files) to demonstrate how it works under the hood.
The basic idea is that you’ve got a working directory that contains all your (source code) files. Because it is great to be able to go back to previous states of the directory, you introduce the concept of revisions: Every time you wish to make a new revision, you create a copy of the working directory. After a while, you would end up with a bunch of directories:
$ ls
working_dir
rev01
rev02
To go back to rev01, you could then take the content of that directory and copy it over the files in working_dir. If you wanted to save disk space, you could put all revisions into a zipped archive:
$ ls
working_dir
rev01_02.tgz
This analogy to Git is mostly accurate, except for one detail: When backing-up your working directory (by creating copies of working_dir), you would probably copy all the files, no matter if they have changed or not.
As we will see, Git behaves differently.
Difference to Git
Git uses objects of type blob to store file contents. Once created, they are re-used for as long as possible: Only if the corresponding (file) data is changed, they will be re-created.
Let’s take a look at how those revisions from the naive approach would be represented in Git. First, we create our working directory and put some demo data into it:
mkdir working_dir
cd working_dir
date > foo.txt # Create demo data
To create the first revision, we set up an empty git repository, create a new file and commit that change:
git init
git add foo.txt
git commit -m "First Commit"
We now have an equivalent of the rev01 directory. It is called e568c5c this time – that’s the SHA-1 hash calculated for that commit, as indicated by git log:
$ git log --oneline
e568c5c (HEAD -> master) First Commit
Here you can see all the objects Git has created for us 1:

The only commit object (cyan, e568c5c), indirectly references a blob object (green, e22f10a) via a tree object (brown, 7288723). Note that the actual data from foo.txt is stored within the blob object. Therefore, this object takes up the most disk space compared to the others.
Now let’s create another file and commit that change:
date > bar.txt
git add bar.txt
git commit -m "Second Commit"
We will end up with a repo that looks like this:
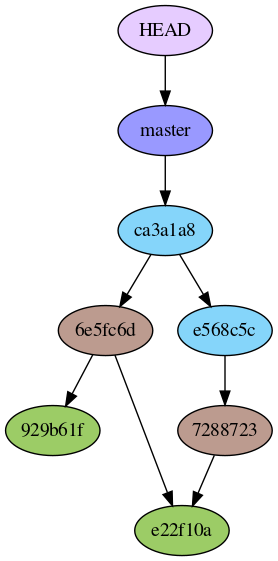
You can see there’s now another commit object (cyan, ca3a1a8), pointing to its parent – the one we created before.
The git graph reveals the subtle difference mentioned in the beginning: While a new blob object 929b61f has been created for storing the content of bar.txt, the existing one for foo.txt is simply re-used by the new tree object. You can tell that from the figure: two tree objects are pointing to a single blob object.
Conclusion
We have seen that the naive approach for making revisions doesn’t completely align with what Git is doing. It is similar, but different in an important detail, as we were able to tell from some graphical representation of a Git repo.