What does it mean that we talk about snapshots of our Git repository, while in Subversion we think in terms of file changes? For me at least, the key to understanding Git is that every commit is, in fact, a snapshot of the entire project. Not a list of patches. Not a difference to the previous commit. Just a snapshot of the whole thing.
Git snapshots everything, they said. Coming from Subversion, this is hard to believe. How would a version control system scale if it stored the entire project state again and again, with each and every commit?
First, let’s do a little experiment on how one might approach version control intuitively, without considering neither Git nor Subversion.
Poor Man’s Version Control
Let’s say we have a project called myapp stored in a directory of that name. All it contains is a main.c file:
myapp
main.c
Without version control, how would you track changes in order to be able to restore a particular state later? Easy enough, you might say: Just create a copy of the entire myapp directory and call it something like myapp-<version>. After a while, you would end up with a bunch of backup directories:
myapp-01
main.c
myapp-<...>
main.c
myapp-<N>
main.c
To step back to a previous state in history, you might go and replace the entire myapp directory by one of these snapshots created previously.
In order to avoid wasting space by keeping so much redundant information, you might consider putting everything into a gzipp’ed archive and deleting all the backup directories:
tar -cvzf myapp.tgz myapp-*
rm -r myapp-*
Interestingly, this naive approach is not completely different from the way Git actually works.
How Git does it
Every time you create a commit, Git takes the content of each added or modified file, compresses it and stores it in an internal object database together with a commit object that holds some meta information1. This approach makes it easy to reason about, as it’s no more difficult than what we’ve done in the simple attempt mentioned above.
You may realize a big drawback here though: Although individual file contents are compressed – which is fine–, even small changes between commits will cause massive duplication inside the object database.
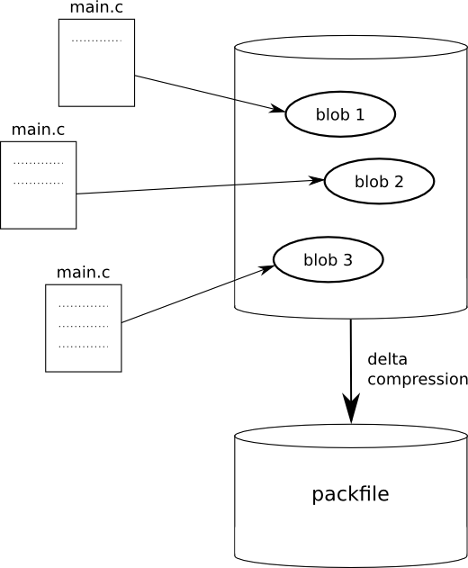
In Git, this scalability problem is simply ignored at the first stage and solved later on. In a process called packing, all the objects are delta compressed and moved into one or more packfiles. This is done on several occasions; you can enforce it using git gc --aggressive.
The drawing below shows a simplified illustration of the storage of compressed file content into blob objects as well as the packfile generation.
Conclusion
Even for everyday Git usage it is vitally important to understand a bit of its inner workings; it’s good to see that the basic idea is not inherently complex but more or less identical with what we might come up with anyway.
This understanding gives us the power to get a grasp of all the more advanced features like branching, merging and rebasing.
References
-
For all the details please refer to the section Git Objects of the excellent Pro Git book. ↩